Analyzing source code
This document shows how DeepScan analyzes your files in the repository.
Analysis
If you add your GitHub repository as a project, DeepScan will try to analyze your JavaScript code in the repository. The following describe this:
- Once you add a project for your repository,
- DeepScan fetches the code of default branch from the repository.
- DeepScan analyzes the code. It can take a few minutes when the repository is large or the service is busy for other requests.
Basically, the following JavaScript and TypeScript files in the project are analyzed.
*.js*.jsx*.mjs*.ts*.tsx*.vue*.astro
Automatic analysis
Automatic analysis means the analysis automatically occurred by the following changes:
- When new commit is pushed to the branches you have been analyzed
- When new pull request is created
- When new change is pushed to a pull request
DeepScan can get notified this changes by webhooks from GitHub. DeepScan will automatically and continuously analyze these changes so you can manage the up-to-date status of your repository and check new code as an automated code review.
Automatic analysis by webhooks just works because DeepScan tries to configure your repository with webhooks when you add a project.
If you want to disable our automatic analysis, go to the settings of your repository on GitHub, delete our
webhook under Webhooks. (Note that its url starts with https://deepscan.io.)
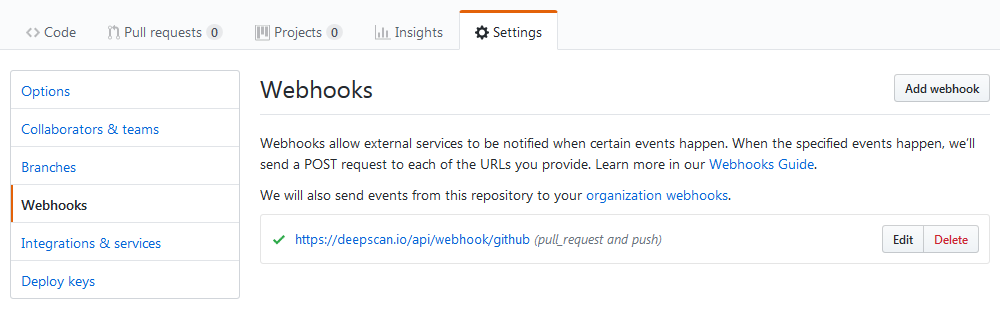
But keep in mind that at least one of your team members should have an owner permission for the repository because the pull request status checks require the permission. In case all of your team members do not have an owner permission, you can see an warning like:
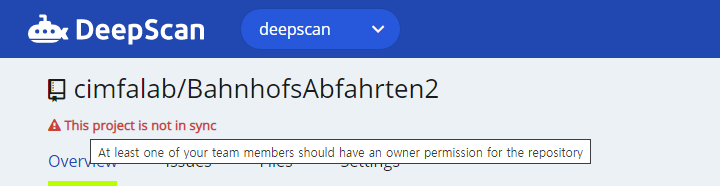
Once one of your team members get to have an owner permission for the repository, an automatic analysis will resume the pull request check hereafter.
Pull request analysis
By the webhooks added in creating a project, DeepScan automatically analyzes the pull request commit whenever a new pull request is created and/or updated for your repository.
After calculating new and resolved issues between the pull request commit and the base one, DeepScan sends the status check to the repository according to the Commit Status setting in the project settings:
| New issues | Resolved issues | Status check | Commit status setting |
|---|---|---|---|
| No new issues | - | Success | |
| New issues | Unresolved issues | Success | Set commit status success always |
| Failure only when the issues with High impact are found | High issues are found | ||
| Failure only when the issues with High or Medium impacts are found | Medium or higher issues are found | ||
| Failure | Low or higher issues are found (default) | ||
| All issues resolved | Success | ||
You can see the above status check in your GitHub page and by clicking Details link, you can see the detailed issues in the DeepScan dashboard.
Also, you can manage the issue status for the pull request. For example, you can set the status as 'False Positive' so the overall status will be changed as 'Success'.
Excluding from an analysis
Excluded files by default
While DeepScan tries to analyze all the JavaScript and TypeScript files, some files are not analyzed by default.
Conditions for these files are as follows:
- All files under
node_modulesandbower_componentsdirectory. - Minified file:
*.min.js,*-min.js,*_min.jsor when average line length is greater than 200. - Automatically generated
*.jsfiles from TypeScript files. - Files over 30,000 lines.
- Files over 1.5 MB in size.
- Lines with length greater than 400.
Excluding unwanted files from an analysis
In the first analysis, it's likely that third-party libraries, test and distribution files are included and the result is somehow distorted.
For excluding files and folders, see here.
Excluding unwanted rules from an analysis
We analyze JavaScript code according to the pre-defined rule set. All available rules are checked by default and you can see the applied rules in the project's Settings > Rules.
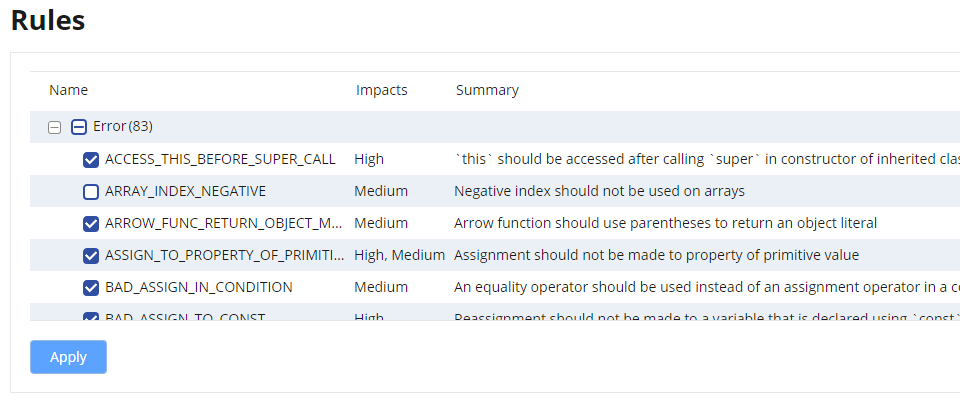
You can choose which rules to apply by selecting and de-selecting them. You need to reanalyze the project for the changed rules to take effect.
For excluding rules, see here.
Excluded rules from the test case code
In test cases, repetitive code may be present to test various aspects of the test target. As a result, some rules at Code Quality category have significantly more violations at test code. However, they are usually harmless because test cases have clear measures of success and failure.
So, the following alarms on test case code are excluded automatically to reduce noise and fixing the detected alarms as smooth as possible:
Currently, BDD, TDD and QUnit style test cases are automatically recognized.
Understanding the analysis result
After analyzing by the rules, we calculate project’s overall grade by aggregating the issues detected. A grade represents status on your project measured by issue density—i.e., the number of issues per thousand lines of code.
You can use this grade as a badge like  to see the latest status directly in GitHub.
to see the latest status directly in GitHub.
To add a badge to your repository, copy markdown or html snippet in the project's Overview into where you want to add, like README file in the GitHub repository. With this badge, you can check the latest status and navigate to the dashboard when you click.
For more information how grades are calculated, see here.